一,MySQL的sql执行流程
MySQL 可以分为 Server 层和存储引擎层两部分。
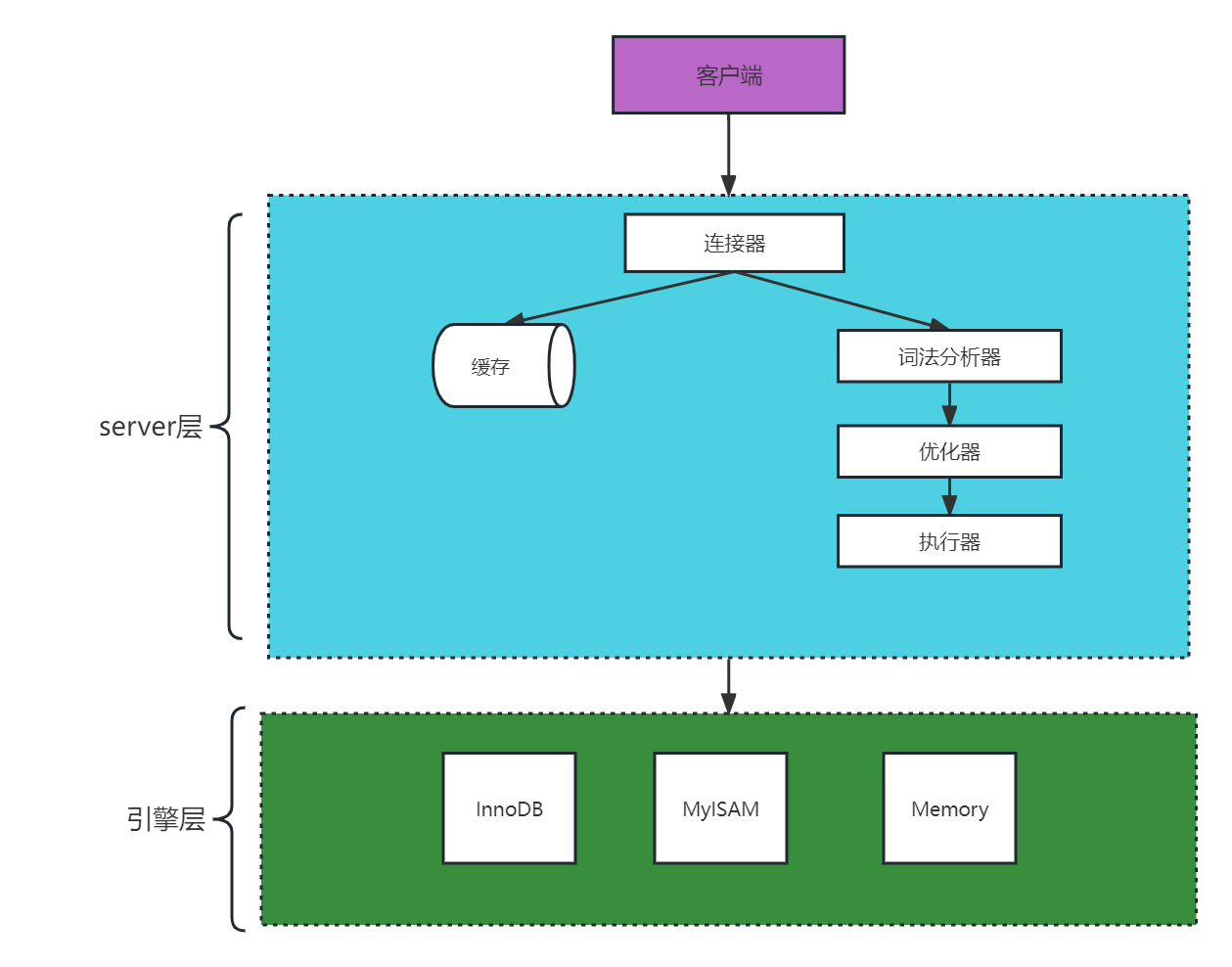
server层的核心组件:
- 连接器:负责管理连接和权限校验。
- 缓存:每次SQL查询时会先去缓存里面查询,缓存里面key为SQL,value为结果集。
- 分析器:对SQL语句进行语法分析和词法分析,方便后续执行。
- 优化器:选择最优的索引和语句执行计划生成。
- 执行器:使用引擎接口,返回查询对应的结果集。
存储引擎层:
存储引擎负责数据的存储和提取。其架构模式是插件式的,支持 InnoDB、MyISAM、Memory 等多个存储引擎。现在最常用的存储引擎是 InnoDB它从 MySQL 5.5.5 版本开始成为了默认存储引擎。也就是说如果我们在create table时不指定表的存储引擎类型,默认会给你设置存储引擎为InnoDB
1.1 连接器
客户端要向mysql发起通信都必须先跟Server端建立通信连接,而建立连接的工作就是有连接器完成的。
连接命令:
mysql ‐h host[数据库地址] ‐u root[用户] ‐p[密码] ‐P[端口默认3306]在完成经典的 TCP 握手后,连接器就要开始认证你的身份,通过判断你输入的用户名和密码:
用户名或密码不对,你就会收到一个"Access denied for user"的错误,然后客户端程序结束执行。
用户名密码认证通过,连接器会为本次连接开辟一个会话空间,查询权限表当前用户拥有的权限保存在会话空间中,之后这个连接里面的权限判断逻辑,都将依赖于此时读到的权限,这就意味着,一个用户成功建立连接后,即使你用管理员账号对这个用户的权限做了修改,也不会影响已经存在连接的权限。修改完成后,只有重新建立的连接才会使用新的权限设置。
用户的权限表在系统表空间的mysql的user表中:
-- 使用默认数据库
use mysql
-- 查询user表
select * from user;
-- 创建新用户 host:%表示所有 或者 localhost表示本地
CREATE USER '用户名'@'host' IDENTIFIED BY '密码';
-- 赋权限,%表示所有(host)
grant all privileges on *.* to 'username'@'host';
-- 刷新数据库
flush privileges;
-- 5.7版本已经不再使用password来作为密码的字段了而改成了authentication_string,所以5.7版本先改列名,再设置用户名密码
alert table user change authentication_string password varchar(100);
-- 设置用户名密码
update user set password=password("123456") where user="root";
-- 查看当前用户的权限
show grants for root@"host";连接完成后,如果你没有后续的动作,这个连接就处于空闲状态,你可以在 show processlist命令查看所有连接情况:
mysql> show processlist;
+----+------+----------------+-------+---------+------+----------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+------+----------------+-------+---------+------+----------+------------------+
| 3 | root | localhost:4943 | mysql | Query | 0 | starting | show processlist |
+----+------+----------------+-------+---------+------+----------+------------------+
1 row in set (0.00 sec)show processlist 的结果中的 Command 列显示为“Sleep”的就表示现在系统里面有一个空闲连接,客户端如果长时间不发送command到Server端,连接器就会自动将它断开。这个时间是由参数 wait_timeout 控制的,默认值是 8 小时。
查看wait_time通过show global variables like "wait_timeout";:
mysql> show global variables like "wait_timeout";
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| wait_timeout | 28800 |
+---------------+-------+
1 row in set, 1 warning (0.00 sec)修改全局服务器关闭非交互连接之前等待活动的秒数通过set global wait_timeout=28800; :
mysql> set global wait_timeout=28800;
Query OK, 0 rows affected (0.00 sec)开发当中我们大多数时候用的都是长连接,把连接放在连接池内进行管理,但是长连接有些时候会导致 MySQL 占用内存涨得特别快,这是因为 MySQL 在执行过程中临时使用的内存是管理在连接对象里面的。这些资源会在连接断开的时候才释放。所以如 果长连接累积下来,可能导致内存占用太大,被系统强行杀掉(OOM),从现象看就是 MySQL 异常重启了。 怎么解决这类问题呢?
1、定期断开长连接。使用一段时间,或者程序里面判断执行过一个占用内存的大查询后,断开连接,之后要查询再重新建立连接。
2、如果你用的是 MySQL 5.7 或更新版本,可以在每次执行一个比较大的操作后,通过执行 mysql_reset_connection 来重新初始化连接资源。这个过程不需要再重新建立连接和重新做权限验证,但是会将连接恢复到刚刚创建完时的状态。
1.2 缓存
大多数情况查询缓存就是个鸡肋,所以在mysql8.0已经移除了查询缓存功能,mysql8.0以前通过设置my.cnf文件中query_cache_type 参数的值控制缓存:
# query_cache_type有3个值 0(OFF)代表关闭查询缓存,1(ON)代表开启,2(DEMAND)代表当sql语句中有SQL_CACHE关键词时才使用缓存
query_cache_type=2这样对于默认的 SQL 语句都不使用查询缓存。而对于你确定要使用查询缓存的语句,可以用 SQL_CACHE 显式指定,像下 面这个语句一样:
select SQL_CACHE * from test where ID = 1;查看当前mysql实例是否开启缓存机制show global variables like "%query_cache_type%"; :
mysql> show global variables like "%query_cache_type%";
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| query_cache_type | DEMAND|
+------------------+-------+
1 row in set, 1 warning (0.00 sec)监控查询缓存的命中率 show status like'%Qcache%';:
mysql> show status like'%Qcache%';
+-------------------------+---------+
| Variable_name | Value |
+-------------------------+---------+
| Qcache_free_blocks | 1 |
| Qcache_free_memory | 1031872 |
| Qcache_hits | 0 |
| Qcache_inserts | 0 |
| Qcache_lowmem_prunes | 0 |
| Qcache_not_cached | 5 |
| Qcache_queries_in_cache | 0 |
| Qcache_total_blocks | 1 |
+-------------------------+---------+
8 rows in set (0.00 sec)- Qcache_free_blocks:表示查询缓存中目前还有多少剩余的blocks,如果该值显示较大,则说明查询缓存中的内存碎片 过多了,可能在一定的时间进行整理。
- Qcache_free_memory:查询缓存的内存大小,通过这个参数可以很清晰的知道当前系统的查询内存是否够用,是多 了,还是不够用,DBA可以根据实际情况做出调整。
- Qcache_hits:表示有多少次命中缓存。我们主要可以通过该值来验证我们的查询缓存的效果。数字越大,缓存效果越 理想。
- Qcache_inserts: 表示多少次未命中然后插入,意思是新来的SQL请求在缓存中未找到,不得不执行查询处理,执行 查询处理后把结果insert到查询缓存中。这样的情况的次数,次数越多,表示查询缓存应用到的比较少,效果也就不理 想。当然系统刚启动后,查询缓存是空的,这很正常。
- Qcache_lowmem_prunes:该参数记录有多少条查询因为内存不足而被移除出查询缓存。通过这个值,用户可以适当的 调整缓存大小。
- Qcache_not_cached: 表示因为query_cache_type的设置而没有被缓存的查询数量。
- Qcache_queries_in_cache:当前缓存中缓存的查询数量。
- Qcache_total_blocks:当前缓存的block数量。
1.3 分析器
语法分析器会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法,如果你的语句不对,就会收到“You have an error in your SQL syntax”的错误提醒,比如下面这个语句 from 写成了 "rom"。
mysql> select * fro user where user=1;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'fro user where user=1' at line 1词法分析器分成6个主要步骤完成对sql语句的分析:
1、词法分析
2、语法分析
3、语义分析
4、构造执行树
5、生成执行计划
6、计划的执行
SQL语句的分析分为词法分析与语法分析,mysql的词法分析由MySQLLex[MySQL自己实现的]完成,语法分析由Bison生成,经过bison语法分析之后,会生成一个这样的语法树:(绿色代表关键字、灰色则代表需进一步拆分)
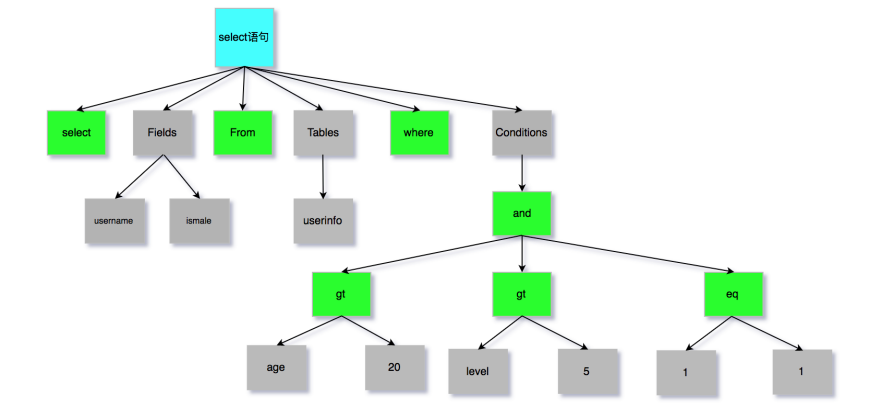
至此我们分析器的工作任务也基本圆满了,关于语法树大家如果想要深入研究可以百度查询这里不过多赘述。
1.4 优化器
其实优化器就是提高我们的执行效率,优化器会根据分析器的树状结构生成多种Sql排列组合,然后结合Mysql的查询算法选择查询效率最快的,比如是否有索引,多个索引如何搭配,多表关联的关联顺序以及那个表为主表等,在挑选出执行效率最佳的之后,会生成一份执行计划,然后由我们的执行器执行。
比如你执行下面这样的语句,这个语句是执行两个表的 join:
select * from test1
inner join test2 on test1.id = test2.id
where test1.name='z' and test2.name='s';- 可以先从表 test1 里面取出 name=z的记录的 ID 值,再根据 ID 值关联到表 test2,再判断 test2 里面 name的 值是否等于 s。
- 也可以先从表 test2 里面取出 name=s的记录的 ID 值,再根据 ID 值关联到 test1,再判断 test1 里面 name 的值是否等于 z。
这两种执行方法的结果是一样的,但是执行的效率会有不同,而优化器的作用就是决定选择使用哪一个方案,可以通过explain 进行索引分析。
1.5 执行器
在看执行器之前如果不了解buffer pool,可以先看1.6buffer pool之后再执行器
1.5.1 select语句执行流程
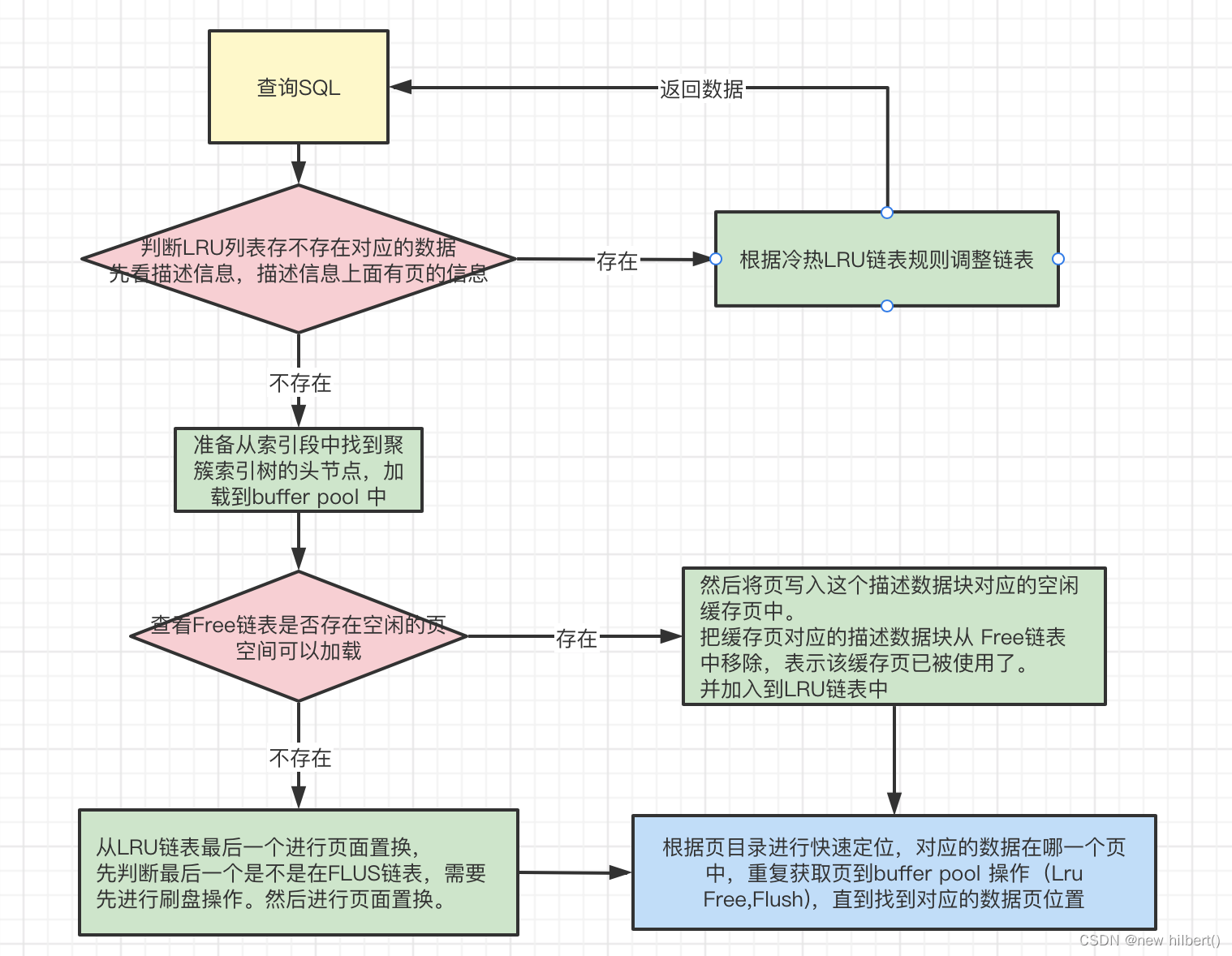
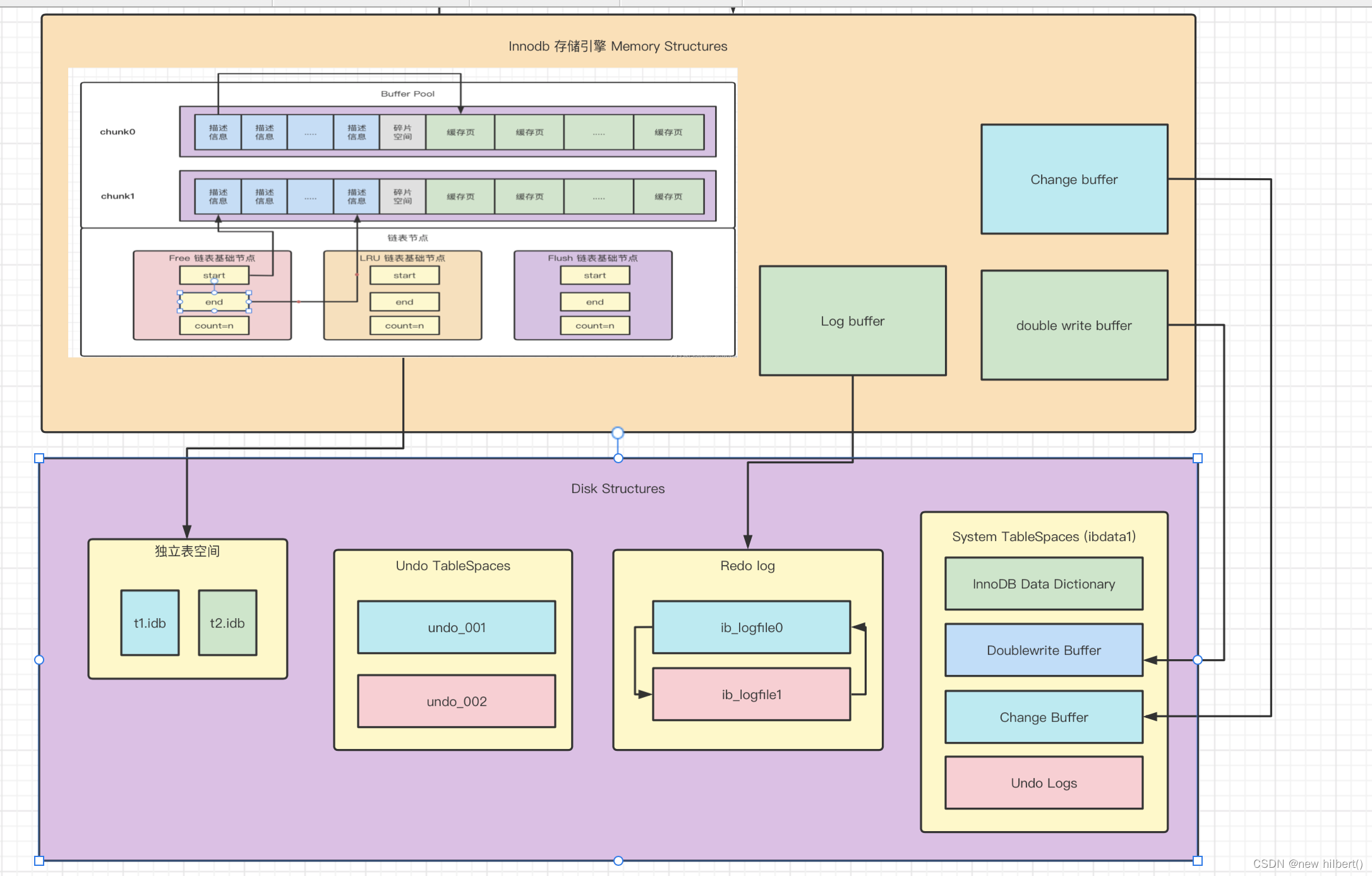
select * from user where id = 1;假设用到主键索引,操作步骤如下:
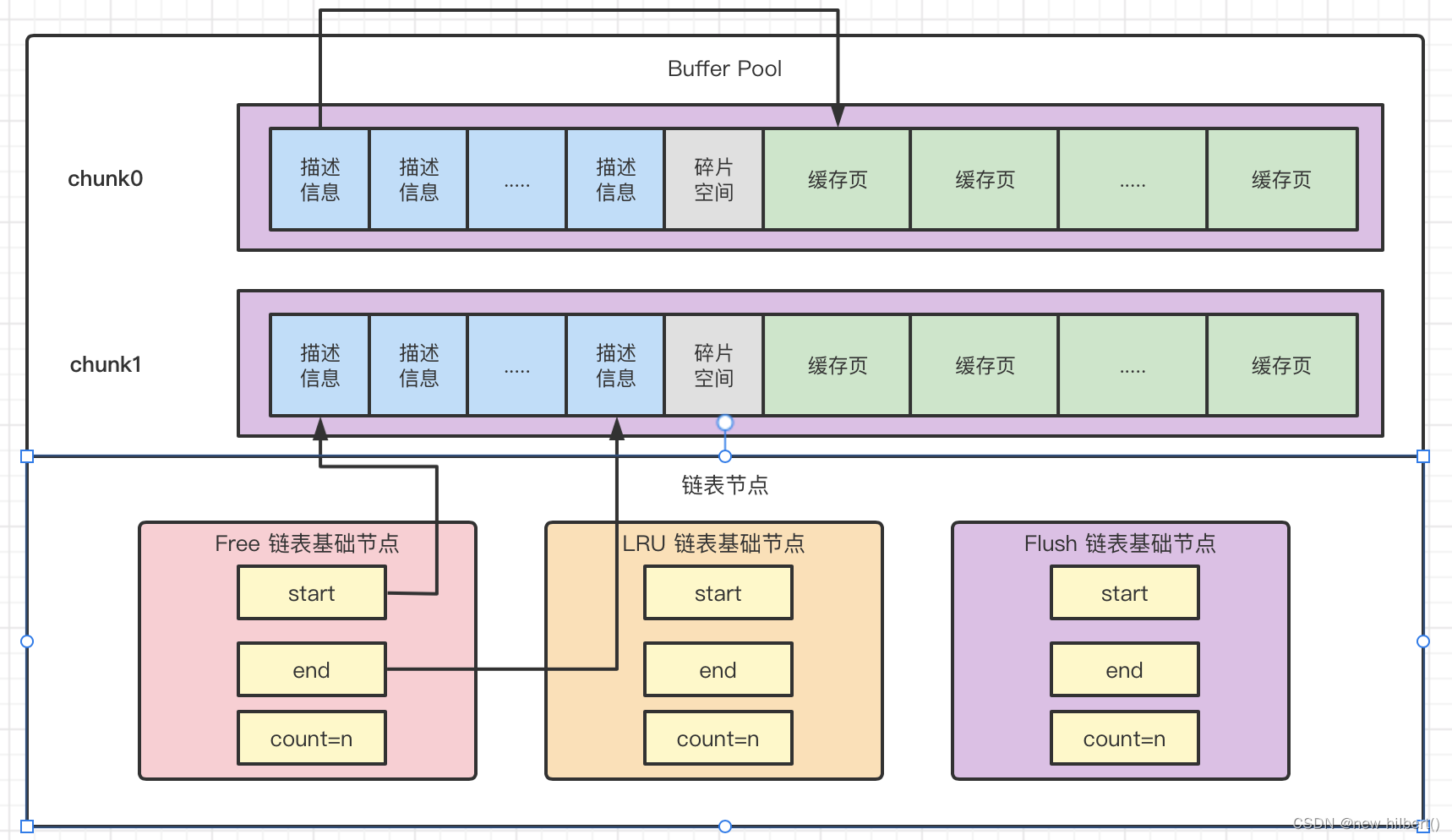
- 判断LRU列表存不存在对应的数据先看描述信息,描述信息上面有页的信息。如果存在,根据冷热LRU链表规则调整链表
- 如果不存在,准备从索引段中找到聚簇索引树的头节点,加载到buffer pool 中
- 查看Free链表是否存在空闲的页空间可以加载。如果存在,将页写入这个描述数据块对应的空闲缓存页中。把缓存页对应的描述数据块从 Free链表 中移除,表示该缓存页已被使用了。并加入到LRU链表中。
- 如果不存在,从LRU链表最后一个进行页面置换,先判断最后一个是不是在FLUS链表,需要先进行刷盘操作。然后进行页面置换。
- 最后根据页目录进行快速定位,对应的数据在哪一个页中,重复获取页到buffer pool 操作(Lru Free,Flush),直到找到对应的数据页位置,然后加载到buffer pool 里面返回数据。
核心流程图如下:
1.5.2insert update delete语句执行流程
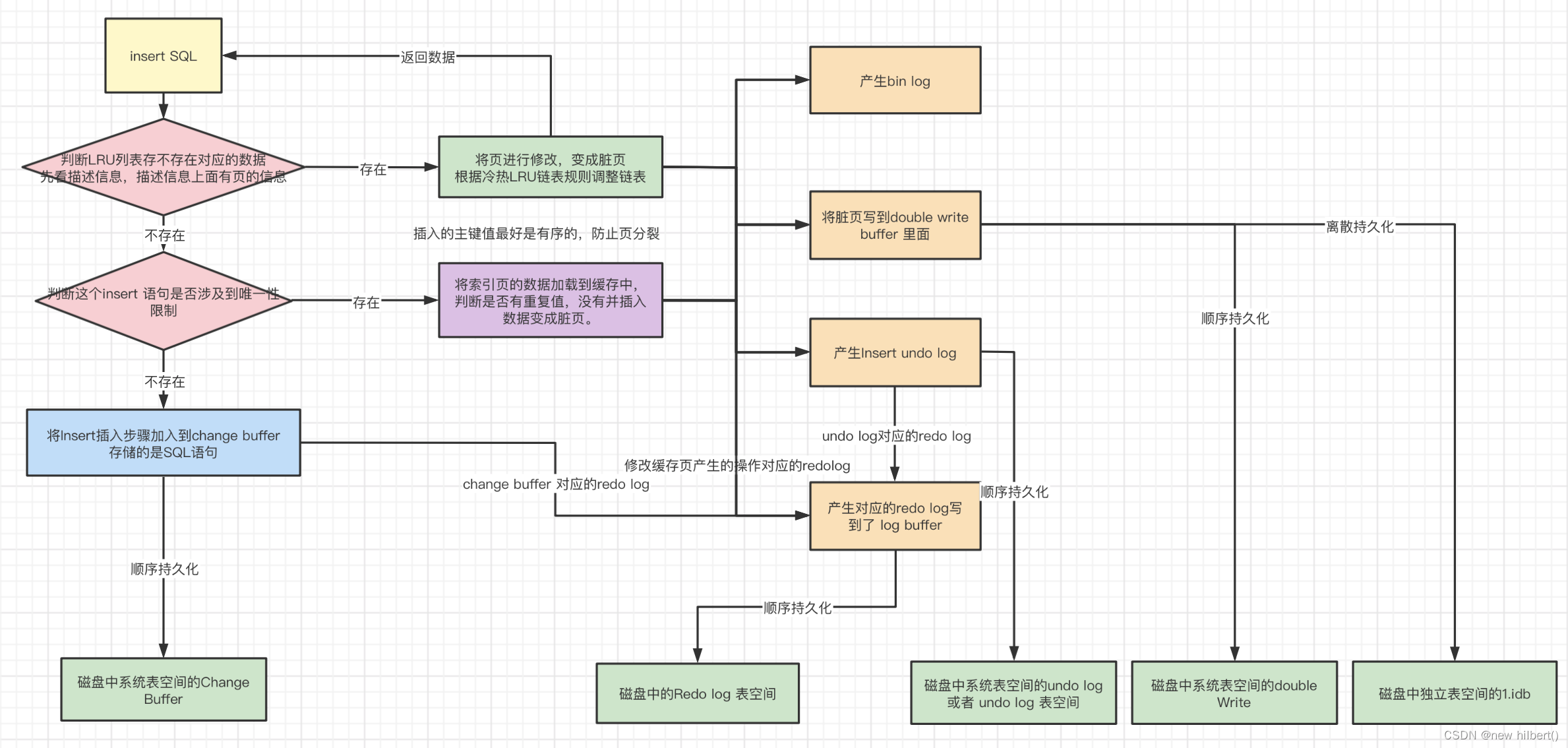
- 判断LRU列表存不存在对应的数据先看描述信息,描述信息上面有页的信息。如果存在,将页进行修改,变成脏页根据冷热LRU链表规则调整链表
- 如果不存在,则判断这个insert 语句是否涉及到唯一性限制。如果存在,将索引页的数据加载到缓存中,判断是否有重复值,没有重复数据就插入数据,使得其变成脏页。
- 如果不存在,则将Insert插入步骤加入到change buffer。(change buffer存储的是SQL语句)
- 生成脏页的时候会产生三种日志 (bin log,redo log和undo log),其中修改缓存页的物理地址改变产生的redo log 和 undo log ,产生的redo log 都会写入到log buffer 里面,最后持久化到磁盘的redo log 表空间的log file,而undo log 则是持久化到undo log 表空间或者磁盘系统表空间的undo log 里面
- 脏页double write 机制
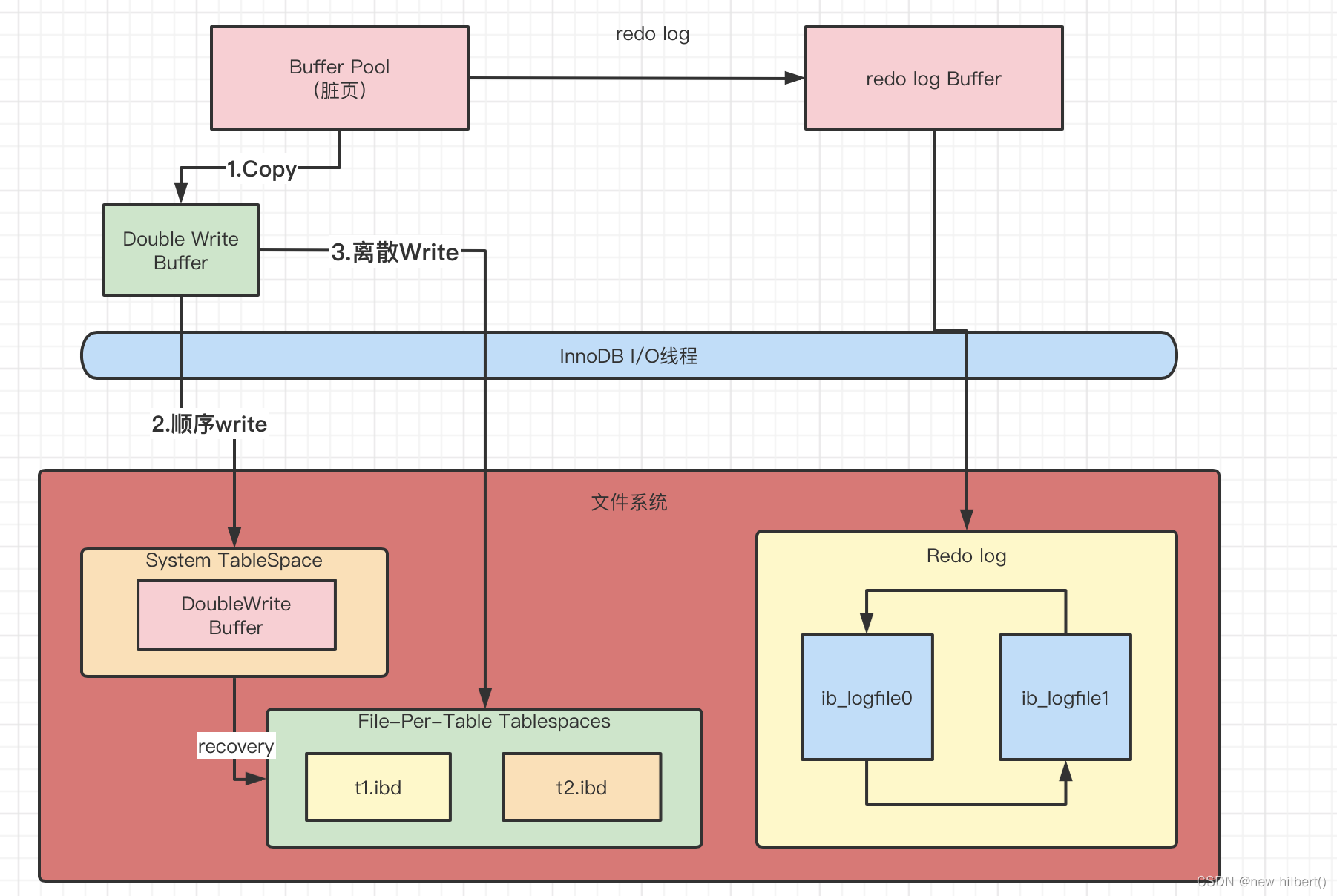
6.change buffer的修改也会产生对应的redo log,然后也会持久化到系统表空间的Chang buffer里面。
核心流程图如下:
参考链接:https://blog.csdn.net/Prior_SX/article/details/124482524