数据类型和对应的数据结构:
| 数据类型 | 底层结构 |
|---|---|
| String | SDS |
| List | 双向列表,压缩列表 |
| Hash | 压缩列表,Hash表 |
| Set | 整数集合,Hash表 |
| SortedSet | 压缩列表,跳表 |
一,String
1.1 常见命令
redis的键是String类型:
# 查看当前库中的所有key
keys *
# 查看key是否存在
exists key
# 查看key的类型
type key
# 查看key对应值的底层编码
object encoding key
# 删除指定的key
del key
# 非阻塞删除key的value
unlink key
# 设置过期时间
expire key 时间【单位 秒】
# 查看还有多少秒过期,-1表示永不过期;-2表示已经过期;
ttl key
# 查看key的数量
dbsize
# 清空当前库
flushdb
# 通杀全部库
flushallredis的值是String类型:
# 存储
set key value
# 设置多个值
mset key1 value1 key2 value2 ...
# 存储的时候设置过期时间
setex key 过期时间【单位 秒】 value
# 获取
get key
# 获取多个值
mget key1 key2 key3
# 获取value的部分值
getrange key 起始位置 结束位置
# 获取原来的,并放置一个新的
getset key value
# 存在不增加,不存在添加
setnx key value
# 数值递增
incr key
# 数值递增,并指定步长
incrby key increment
# 数值递减
decr key
# 数值递减,并指定步长:
decrby key decrement
# 向尾部追加值
append key value
# 获取字符串长度
strlen key1.2 应用场景
- 缓存对象:直接缓存整个对象的 JSON 或者 采用将 key 进行分离为
user:ID:属性 - 常规计数: Redis 处理命令是单线程,所以执行命令的过程是原子或者使用lua脚本执行多条命令也是原子的,因此适合计数场景,比如计算访问次数、点赞、转发、库存数量等等。
- 分布式锁:可以用它来实现分布式锁。
- 共享 Session 信息:将Session ID作为key。
1.3 数据结构
redis 中所有的 key 都是字符串,这些字符串是通过一个名为简单动态字符串 SDS 的数据结构实现的。
struct sdshdr? { // SDS header,[?] 可以为 8, 16, 32, 64
uint?_t len; // 已用空间,字符串的实际长度
uint?_t alloc; // 已分配空间,不包含'\0'
unsigned char flags; // 类型标记,指明了 len 与 alloc 的实际类型,可以通过 sds[-1] 获取
char buf[]; // 字符数组,保存以'\0'结尾的字符串,与传统 C 语言中的字符串的表达方式保持一致
};内存布局如下:

如果通过append key value向字符串追加值,可以通过 alloc - len计算出剩余的空间大小,用来判断空间是否可以存放,如果不满足的话,就会自动进行扩容,扩容的空间一般要高于实际所需空间,采用预分配冗余空间的方式来减少内存的频繁分配。当字符串长度小于1M时,扩容都是加倍现有的空间,如果超过1M,扩容时一次只会多扩1M的空间。需要注意的是字符串最大长度为512M。
二,List
2.1 常见命令
# 从左边或右边插入值
lpush/rpush key value1 value2 value3 .....
# 从左边或右边取出一个值,取出的值就不在list中
lpop/rpop key
# 从key1List右边取值,取出的值添加到key2List左边
rpoplpush key1 key2
# 从下标为index,取len长度的值。 index = 0 len = -1表示查询所有
lrange key index len
# 取某个下标值
lindex key index
# 获取列表的长度
llen key
# 在某个值value的前面或后面插入新值newvalue
linsert key before/afert value newvalue
# 表示删除左边len个值为value的数据
lrem key len value
# 将下标为index的值替换为newvalue
lset key index newvalue2.2 应用场景
- 队列:按先进先出的顺序对数据进行存取的,从左边或右边插入值
lpush/rpush,然后从右边或左边取值rpop/lpop,使用brpop命令也称为阻塞式读取,客户端在没有读到队列数据时,自动阻塞,直到有新的数据写入队列,再开始读取新数据和消费者程序自己不停地调用RPOP命令相比,这种方式能节省CPU开销。缺点是List 不支持多个消费者消费同一条消息,因为一旦消费者拉取一条消息后,这条消息就从 List 中删除了,无法被其它消费者再次消费。 - 栈:按先进后出的顺序对数据进行存取的,这样就可以实现如我们关注了订阅号,当点开订阅号消息时,订阅号都会显示最近发表的前1~4条文章,后发表的文章先出现
2.3 数据结构
2.3.1 双向链表LinkedList
双向链表LinkedList的数据结构:
typedef struct list {
listNode *head; // 链表头节点
listNode *tail; // 链表尾节点
void *(*dup)(void *ptr);// 节点值复制函数
void (*free)(void *ptr);// 节点值释放函数
int (*match)(void *ptr, void *key);// 节点值比较函数
unsigned long len;// 链表节点数量
} list;链表节点的数据结构:
typedef struct listNode {
struct listNode *prev; // 前置节点
struct listNode *next; // 后置节点
void *value; // 节点值
} listNode;内存布局如下:
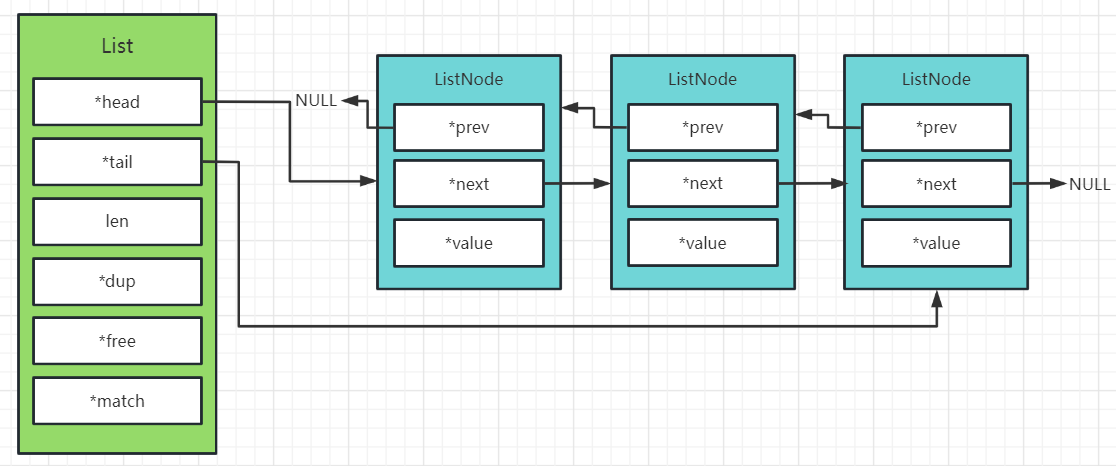
链表最大的优点就是维护起来比较简单,缺点是链表每个节点之间的内存都是不连续的,意味着无法很好利用 CPU 缓存,还有一点,就是内存开销较大,因此Redis 3.0 的 List 对象在数据量比较少的情况下,会采用「压缩列表」作为底层数据结构的实现,它的优势是节省内存空间,并且是内存紧凑型的数据结构。
2.3.2 压缩列表zipList
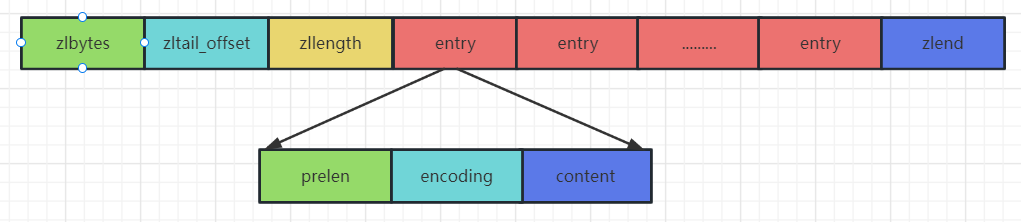
压缩列表zipList的数据结构:
typedf struct ziplist<T>{
int32 zlbytes; // 压缩列表占用字符数
int32 zltail_offset; // 最后一个元素距离起始位置的偏移量,用于快速定位最后一个节点
int16 zllength; // 元素个数
T[] entries; // 元素内容entry
int8 zlend; // 结束位 0xFF
}ziplist下面是entry的数据结构:
typede struct entry{
int<var> prelen; // 前一个entry的长度
int<var> encoding; // 元素类型编码
optional byte[] content; // 元素内容
}entry内存布局如下:
连锁更新
entry中有一个prelen字段,它的长度要么是1个字节,要么都是5个字节:
- 前一个节点的长度小于254个字节,则prelen长度为1字节;
- 前一个节点的长度大于254字节,则prelen长度为5字节;
假设现在有一组压缩列表,entry的长度都在250253字节之间,现在突然新增一个entry节点,这个entry节点长度大于254字节。由于新的entry节点大于等于254字节,这个新增entry节点后面entry的prelen就变成为5个字节,而他本身就是在250253字节之间,当entry的prelen就变成为5个字节,必定会超过254个节点,那随后会导致其余的所有entry节点的prelen增大为5字节。
示意图如下所示:

同样地,删除操作也会导致出现连锁更新这种情况。
双向链表和压缩列表对比:
- 双向链表LinkedList便于在表的两端进行push和pop操作,在插入节点上复杂度很低,但是它的内存开销比较大。首先,它在每个节点上除了要保存数据之外,还有额外保存两个指针;其次,双向链表的各个节点都是单独的内存块,地址不连续,容易形成内存碎片
- zipList存储在一块连续的内存上,所以存储效率很高。但是它不利于修改操作,插入和删除操作需要频繁地申请和释放内存。特别是当zipList长度很长时,一次realloc可能会导致大量的数据拷贝
2.3.3 快速列表 quickList
在Redis3.2版本之后,list的底层实现方式又多了一种,quickList。qucikList是由zipList和双向链表linkedList组成的混合体。它将linkedList按段切分,单个节点使用zipList来紧凑存储,多个zipList之间使用双向指针串接起来。
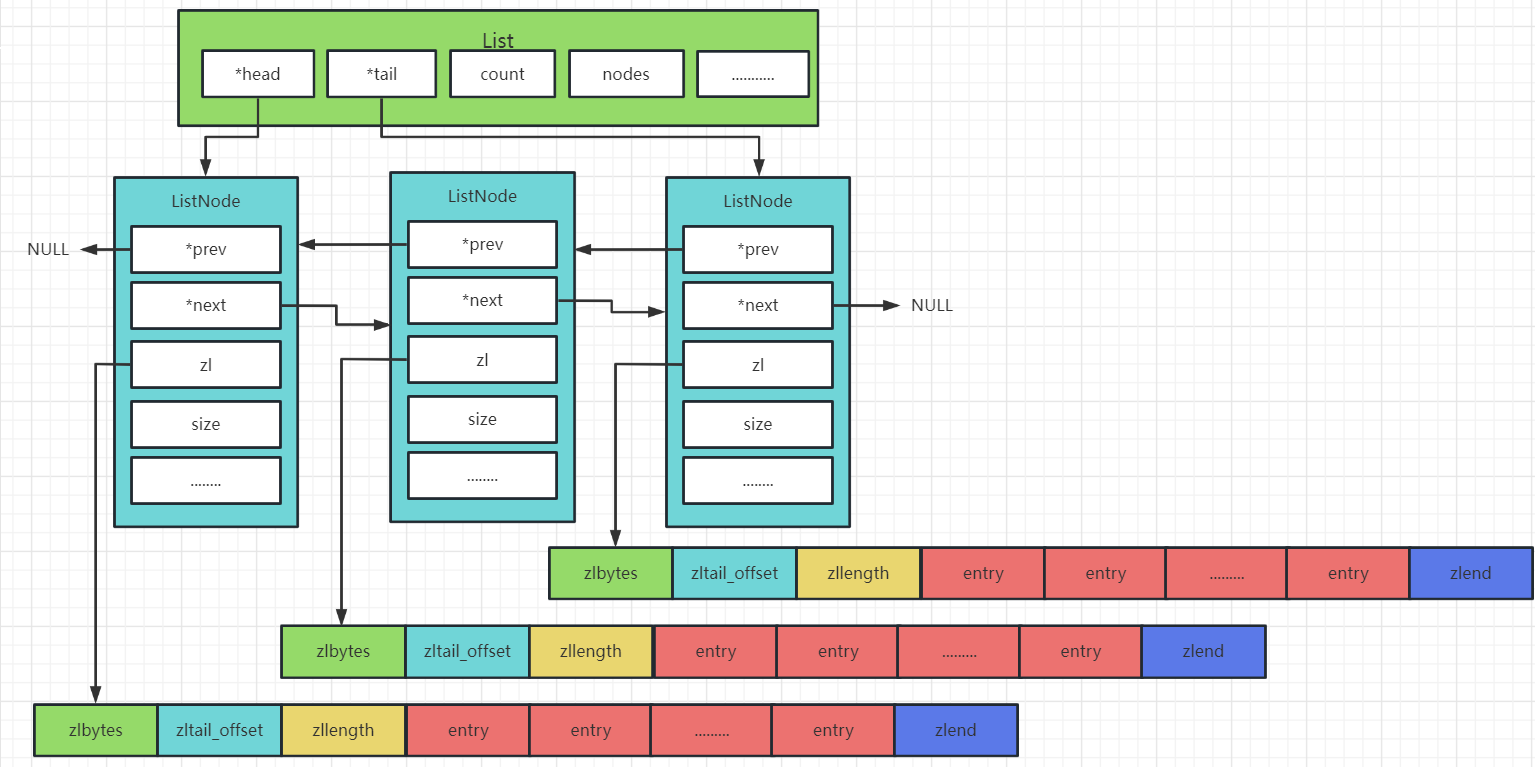
qucikList的数据结构:
typedf struct quicklist{
quicklistNode* head; // 指向头结点
quicklistNode* tail; // 指向尾节点
long count; // 元素总数
int nodes; // quicklistNode节点的个数
int compressDepth; // 压缩算法深度
...
}quickListquicklistNode的数据结构:
typedf struct quicklistNode{
quicklistNode* prev; // 前一个节点
quicklistNode* next; // 后一个节点
ziplist* zl; // 压缩列表
int32 size; // ziplist大小
int16 count; // ziplist 中元素数量
int2 encoding;// 编码形式 存储 ziplist 还是进行 LZF 压缩储存的zipList
...
}quickListNode示意图如下所示:
打开redis.conf文件:
# quickList中每个ziplist节点可以存储多个元素,quickList内部默认单个zipList长度为8k字节,即list-max-ziplist-size为 -2,超出了这个阈值,就会重新生成一个zipList来存储数据。性能最好的时候就是就是list-max-ziplist-size为-1和-2,即分别是4kb和8kb的时候,当然,这个值也可以被设置为正数,当list-max-ziplist-szie为正数n时,表示每个quickList节点上的zipList最多包含n个数据项
list-max-ziplist-size -2
# 压缩深度,quickList中可以使用压缩算法对zipList进行进一步的压缩,这个算法就是LZF算法,这是一种无损压缩算法,list-compress-depth这个参数表示一个quickList两端不被压缩的节点个数,例如list-compress-depth为1,表示quickList的两端各有1个节点不进行压缩,中间结点开始进行压缩;
list-compress-depth 0三,Hash
3.1 常用命令
# 插值:给<key>集合中的<field>键赋值<value>
hset <key> <field> <value>
# 取值:从<key>集合<field>取出value
hget <key> <field>
# 批量插值:批量设置hash的值
hmset <key1> <field1> <value1> <field2> <value2> ...
# 判断filed是否存在:查看哈希表 key 中,给定域 field 是否存在
hexists <key> <field>
# 获取一个hash类型的key中的所有的field和value
hgetall key
# 获取所有的filed:列出该hash集合的所有field
hkeys <key>
# 获取所有的value:列出该hash集合的所有value
hvals <key>
# 增量:为哈希表 key 中的域 field 的值加上步长
hincrby <key> <field> 步长
# 不存在,插值:将哈希表 key 中的域 field 的值设置为 value ,当且仅当域 field 不存在
hsetnx <key> <field> <value>3.2 应用场景
电商系统购物车数据存储,存储的结构为 用户ID为key,商品ID为field,商品数量为value。购物车商品数量+1使用hincrby <key> <field> 步长。
3.3 数据结构
当数据量比较小,或者单个元素比较小时,底层用ziplist存储,详情参考上方。
Hash 数据结构底层实现字典dict数据结构:
typedef struct dict {
dictType *type; // 类型函数,用于实现多态
void *privdata; // 私有数据,用于实现多态
dictht ht[2]; // 哈希表,字典使用 ht[0] 作为哈希表,ht[1] 用于进行 rehash
int rehashidx; // rehash索引,当没有执行 rehash 时,其值为 -1
} dict;哈希表数据结构:
typedef struct dictht {
dictEntry **table; // 哈希表数组,数组中的每个元素是一个单向链表
unsigned long size; // 哈希表数组大小
unsigned long sizemask; // 哈希掩码,用于计算索引
unsigned long used; // 已有节点数量
} dictht;哈希表节点数据结构:
typedef struct dictEntry {
void* key; // 键
union { // 值,可以为指针、有符号长整,无符号长整,双精度浮点
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;整体存储结构:
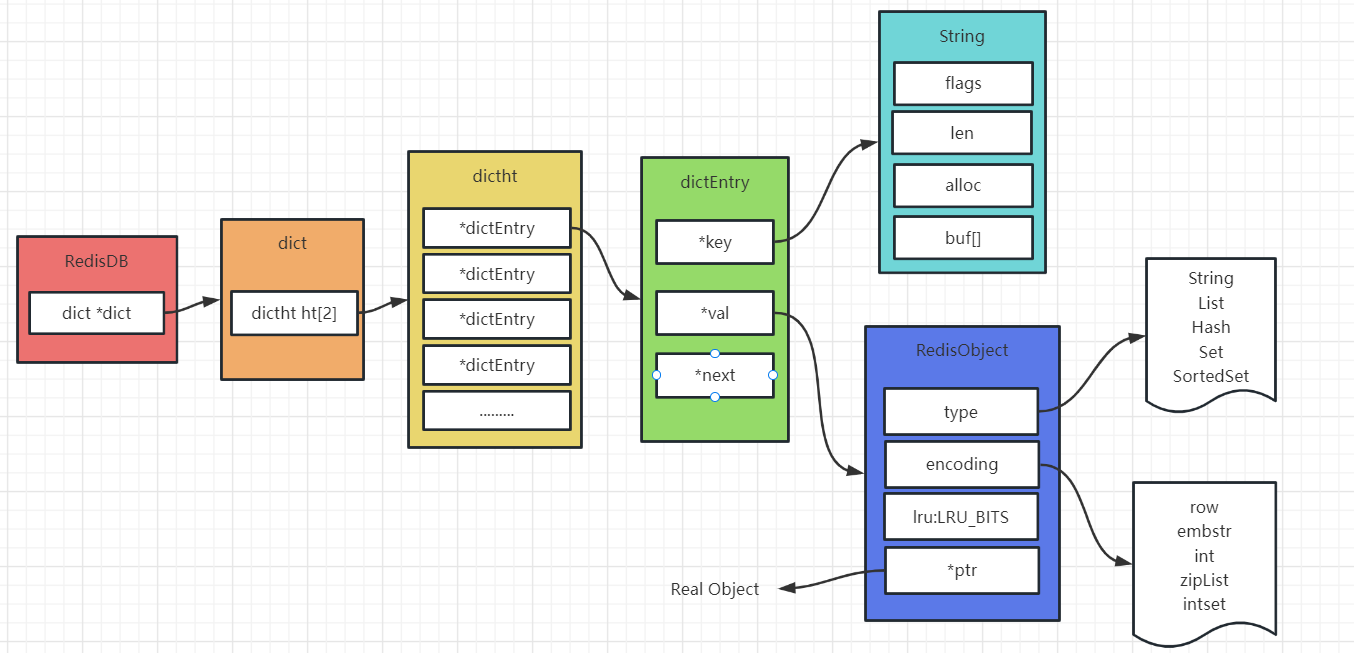
3.2.1 渐进式rehash
dict数据结构中哈希表定义了两个dictht ht[2],之所以定义了 2 个哈希表,是因为进行 rehash 的时候,需要将哈希表 1中的所有值迁移到哈希表2中。
①,rehash 的步骤:每次哈希表元素进行新增、删除、查找或者更新操作时,Redis除了会执行对应的操作之外,还会顺序将哈希表 1中索引位置上的所有 key-value 迁移到哈希表 2上;随着处理客户端发起的哈希表操作请求数量越多,最终在某个时间点会把哈希表 1的所有 key-value 迁移到哈希表2,从而完成rehash 操作,这样就巧妙地把一次性大量数据迁移工作的开销,分摊到了多次处理请求的过程中,避免了一次性 rehash 的耗时操作。
②,rehash 触发条件:rehash 的触发条件跟负载因子有关,负载因子 = hash表已保存的节点数量 / hash表大小
- 当负载因子大于等于 1 时,Redis 没有在执行 bgsave 命令或者 bgrewiteaof 命令,也就是没有执行 RDB 快照或没有进行 AOF 重写的时候,就会进行 rehash 操作
- 当负载因子大于等于 5 时,此时说明哈希冲突非常严重了,不管Redis 有没有在执行 RDB 快照或 AOF 重写,都会强制进行 rehash 操作
四,Set
4.1 常用命令
# 添加:将一个或多个 member 元素加入到集合 key 中,已经存在的 member 元素将被忽略
sadd <key> <value1> <value2>.....
# 取出该集合的所有值
smembers key
# 判断集合<key>是否为含有该<value>值,有1,没有0
sismember <key> <value>
# 返回该集合的元素个数
scard <key>
# 删除集合中的元素
srem <key> <value1> <value2>.....
# 随机从该集合中取出n个值,取出的值会从集合中删除
spop <key> <n>
# 随机从该集合中取出n个值,取出的值不会从集合中删除
srandmember <key> <n>
# 把集合中一个值从一个集合移动到另一个集合
smove <source> <destination> value
# 返回两个集合的交集元素
sinter <key1> <key2>
# 返回两个集合的并集元素
sunion <key1> <key2>
# 返回两个集合的差集元素(key1中的,不包含key2中的)
sdiff <key1> <key2>4.2 应用场景
- 抽奖活动:一次抽奖多个用户,例如参与抽奖的用户有10个,一次抽取2个用户作为中奖用户,使用
smembers key查看所有抽奖成员,使用srandmember <key> <n>抽取n个成员,如果多次抽奖,被开奖的用户不可再次参与,可以使用srandmember <key> <n>抽取成员作为开奖用户,同时会移除已开奖的用户。 - 朋友圈消息点赞成员列表:在微信朋友圈当我点赞朋友的一条消息时,会在下方显示点赞成员列表,这个列表只显示与我是好友点赞成员,不是好友则不显示。那么此时可以使用交集
sinter <key1> <key2>查询 - 查询条件交集,例如电商系统购买电脑时配置选择,
4.3 数据结构
整数集合是 Set 对象的底层实现之一,当一个 Set 对象只包含整数值元素,并且元素数量不大时,就会使用整数集这个数据结构作为底层实现,整数集合数据结构:
typedef struct intset {
uint32_t encoding; // 编码方式,指示元素的实际类型
uint32_t length; // 元素数量
int8_t contents[]; // 元素数组,元素实际类型可能为 int16_t,int32_t,int64_t,
} intset;该数据结构有以下特征:
- 有序:元素数组中的元素按照从小到大排列,使用二分查找时间复杂度为
O(logN) - 升级:当有新元素加入集合,且新元素比所有现有元素类型都长时,集合需要进行升级
升级操作:
整数集合会有一个升级规则,就是当我们将一个新元素加入到整数集合里面,如果新元素的类型(int32_t)比整数集合现有所有元素的类型(int16_t)都要长时,整数集合需要先进行升级,也就是按新元素的类型(int32_t)扩展 contents 数组的空间大小,然后才能将新元素加入到整数集合里,当然升级的过程中,也要维持整数集合的有序性。
整数集合升级的过程不会重新分配一个新类型的数组,而是在原本的数组上扩展空间,然后在将每个元素按间隔类型大小分割,如果 encoding 属性值为 INTSET_ENC_INT16,则每个元素的间隔就是 16 位。
举个例子,假设有一个整数集合里有 3 个类型为 int16_t 的元素:
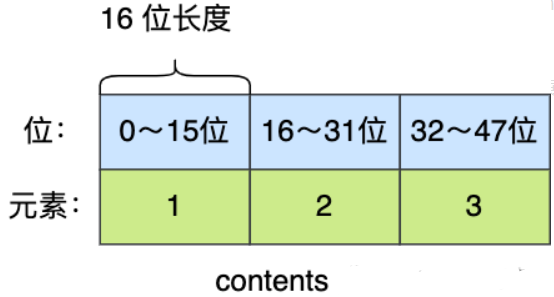
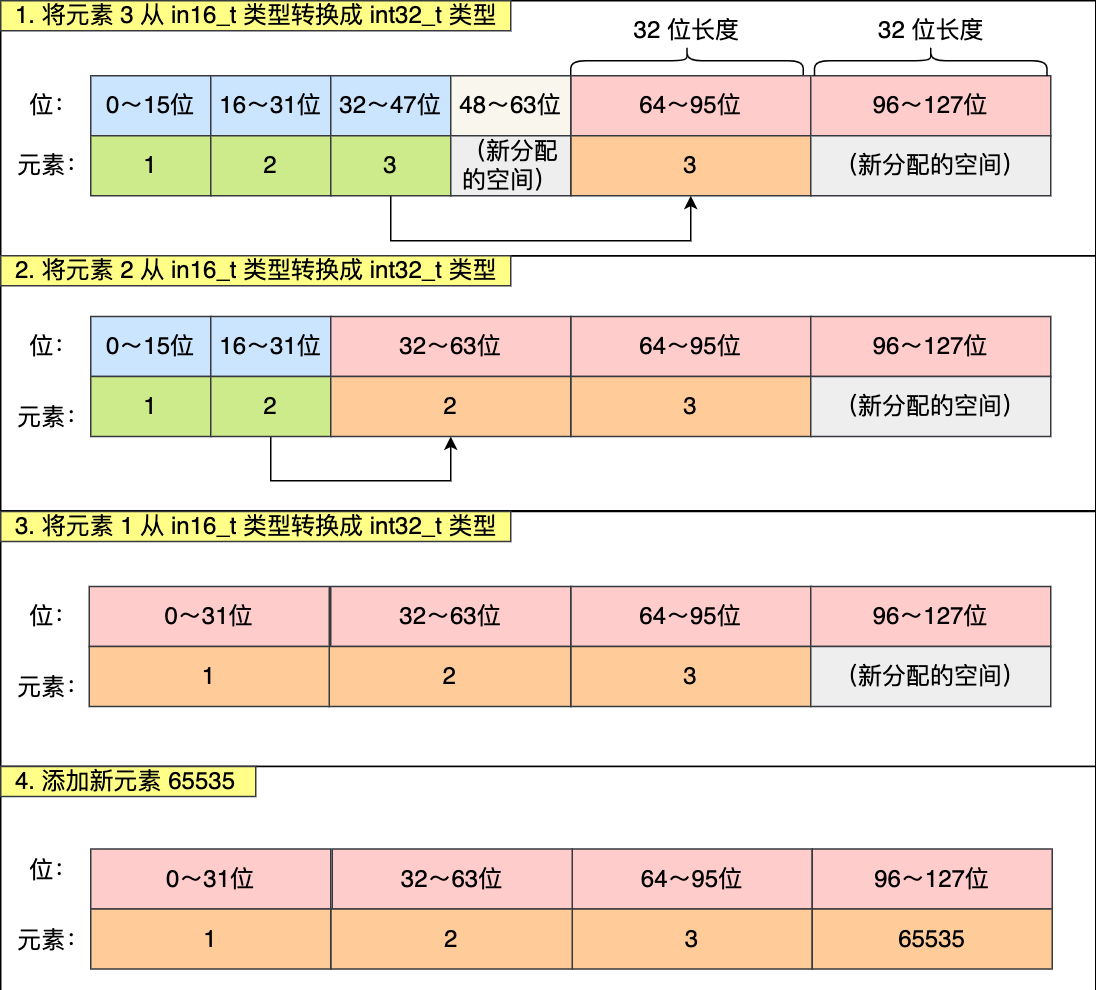
现在,往这个整数集合中加入一个新元素 65535,这个新元素需要用 int32_t 类型来保存,所以整数集合要进行升级操作,首先需要为 contents 数组扩容,在原本空间的大小之上再扩容多 80 位(4x32-3x16=80),这样就能保存下 4 个类型为 int32_t 的元素
扩容完 contents 数组空间大小后,需要将之前的三个元素转换为 int32_t 类型,并将转换后的元素放置到正确的位上面,并且需要维持底层数组的有序性不变,整个转换过程如下:
整数集合升级的好处是节省内存资源,不支持降级操作,当两个条件任意满足时Set将用hashtable存储数据,不在使用整数集合:
- 元素个数大于配置文件配置的数值512个字节时,
set-max-intset-entries 512, - 元素无法用整形表示
五,SortedSet
5.1 常用命令
# 插值:将一个或多个 member 元素及其 score 值加入到有序集 key 当中。
zadd <key> <score1> <value1> <score2> <value2>....
# 返回有序集 key 中,下标在<start> <stop>之间的元素, start=0到stop=-1就是返回全部的元素,从小到大排列,带withscores,可以让分数一起和值返回到结果集。
zrange <key> <start> <stop> [withscores]
# 返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列。
zrangebyscore key min max [withscores]
# 返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员,改为从大到小排列。
zrevrangebyscore key max min [withscores]
# 增量:为键key为,值为value的 score加上increment的增量
zincrby <key> <increment> <value>
# 删除:删除该集合下,指定值的元素
zrem <key> <value>
# 统计该集合,分数区间内的元素个数
zcount <key> <min> <max>
# 排名:返回该值在集合中的排名,从0开始
zrank <key> <value>5.2 应用场景
体育赛事排行榜、新闻热度排行榜,热点排行榜。我们任意打开一个新闻网站,总有块区域显示排行前10的新闻,排行版一般都是根据点击数来排行的,这个点击数就可以使用zincrby <key> <increment> <value> 指令来实现
5.3 数据结构
zset数据结构:
typedef struct zset {
dict *dict; // 维护 member -> score 的映射,查找给的成员的分值
zskiplist *zsl; // 按 score 大小保存了所有集合元素,支持范围操作
} zset;跳表zskiplist数据结构:
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length; // 跳表的节点的个数(不包含头节点)
int level; // 跳表的节点的最大高度(不包括头节点)
} zskiplist;节点数据结构:
typedef struct zskiplistNode {
sds ele; // 该节点所存储的字符串值
double score; // 该节点排序的分值
struct zskiplistNode *backward; // 当前节点最底层的前一个节点,头节点和第一个节点的backward指向NULL
struct zskiplistLevel {
struct zskiplistNode *forward; // 指向同一层的下一个节点,尾节点的forward指向NULL
unsigned long span; // forward指向的节点与本节点之间的节点的个数,span越大说明跳过的节点的个数越多
} level[];
} zskiplistNode;存储结构:
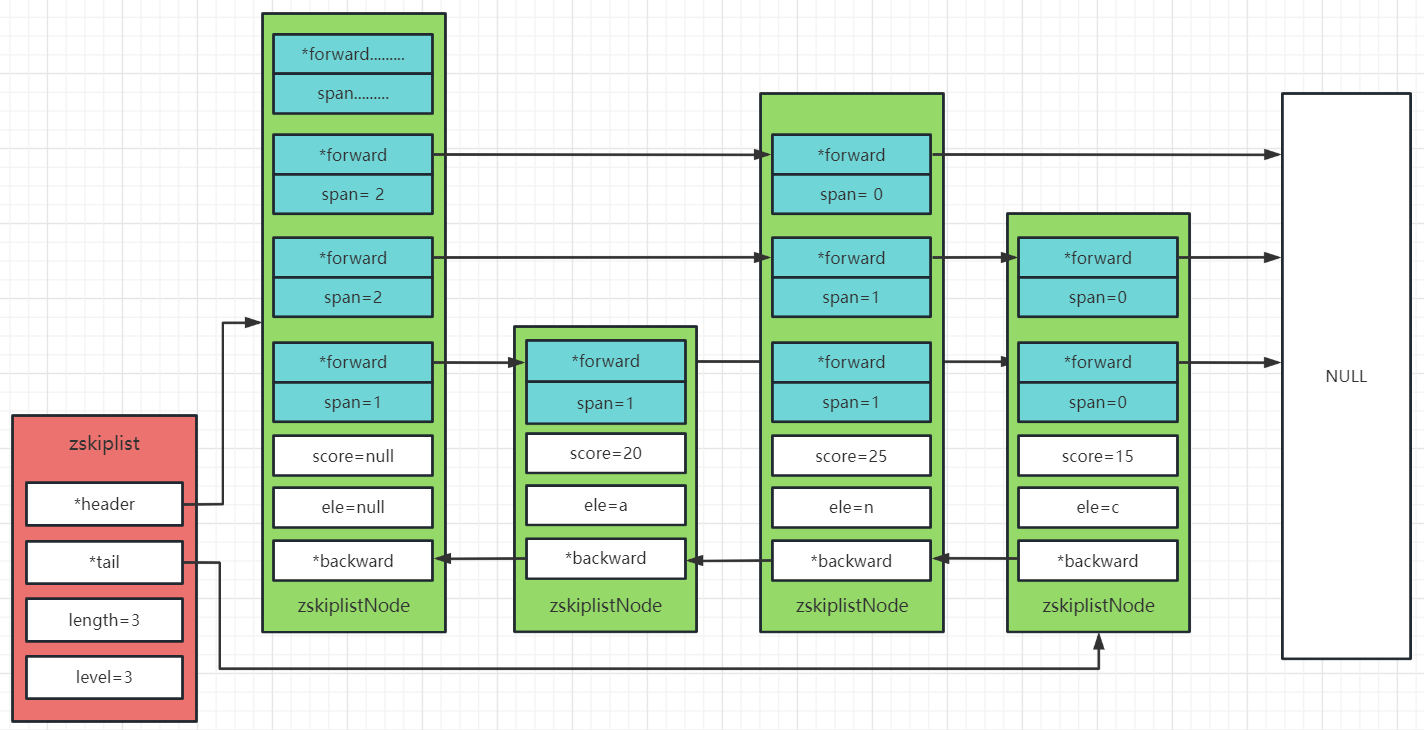
查找和插入节点的方式:
- 查找时候从记录的最高level查找,如果forward指向NULL就向下一层查询。
- 插入节点的高度是随机的,调用zslRandomLevel函数为节点随机生成高度。
有序集合对象有2种编码方案,当同时满足以下条件时,集合对象采用ziplist编码,否则采用skiplist编码:
zset-max-ziplist-value:当 member 的长度都小于该值时使用 ziplist 编码(默认为 64字节)zset-max-ziplist-entries:当 zset 中的元素数量小于该值时使用 ziplist 编码(默认为 128个)
六,BitMaps
6.1 常用命令
# 设置值 value:设置Bitmaps中某个偏移量的值(0或1)offset:偏移量,从0开始
setbit <key> <offset> <value>
# 取值 offset:偏移量,从0开始
getbit <key> <offset>
# 统计 统计字符串从start字节到end字节比特值为1的数量
bitcount <key> [start end]
#bitop是一个复合操作,它可以做多个Bitmaps的and(交集),or(并集),not(非),xor(异或) 操作并将结果保存在destkey中。
bitop (and/or/not/xor) <destkey> [key…]6.2 实现细节
现代计算机用二进制(位) 作为信息的基础单位, 1个字节等于8位, 例如“abc”字符串是由3个字节组成, 但实际在计算机存储时将其用二进制表示, “abc”分别对应的ASCII码分别是97、 98、 99, 对应的二进制分别是01100001、 01100010和01100011,如下图:

合理地使用操作位能够有效地提高内存使用率和开发效率。Redis提供了Bitmaps这个“数据类型”可以实现对位的操作。
Bitmaps本身不是一种数据类型, 实际上它就是字符串(key-value) , 但是它可以对字符串的位进行操作,Bitmaps单独提供了一套命令, 所以在Redis中使用Bitmaps和使用字符串的方法不太相同。 可以把Bitmaps想象成一个以位为单位的数组, 数组的每个单元只能存储0和1, 数组的下标在Bitmaps中叫做偏移量。
Bitmaps经常用来统计较大用户的日活跃。
七,Geospatial
7.1 常用命令
# 添加地理位置(经度,纬度,名称),两极无法直接添加,一般会下载城市数据,直接通过 Java 程序一次性导入,已经添加的数据,是无法再次往里面添加的,有效的经度从 -180 度到 180 度。有效的纬度从 -85.05112878 度到 85.05112878 度。当坐标位置超出指定范围时,该命令将会返回一个错误。
geoadd <key> <longitude> <latitude> <member> [longitude latitude member...]
# geopos 获取某个元素的地理位置经纬度
geoadd <key> <member>
# 获取两个位置之间的直线距离
geodist <key> <member1> <member2> [m|km|ft|mi]
# 以给定的经纬度为中心,找出某一半径内的元素
georadius <key> <longitude> <latitude> 半径 m|km|ft|mi
# georadiusbymember 跟 georadius 命令一样,都可以找出位于指定范围的位置元素,但是这里不是指定中心点坐标,而是指定以哪个元素为中心点。
georadius <key> <member> 半径 m|km|ft|mi7.2 实现细节
geo 底层原理是使用跳表实现,分值是根据经纬度进行geohash的得到值。
geohash 是 2008 年 Gustavo Niemeye 发明用来编码经纬度信息的一种编码方式,比如北京市中心的经纬度坐标是 116.404844,39.912279,通过 12 位 geohash 编码后就变成了 wx4g0cg3vknd,它究竟是如何实现的?其实原理非常简单,就是二分,整个编码过程可以分为如下几步:
第一步:转二进制
上过初中地理的我们都知道,地球上任何一个点都可以标识为某个经纬度坐标,经度的取值范围是东经 0-180 度和西经 0-180 度,纬度的取值范围是北纬 0-90 和南纬 0-90 度。去掉东西南北,可以分别认为经度和纬度的取值范围为[-180,180]和[-90,90]。
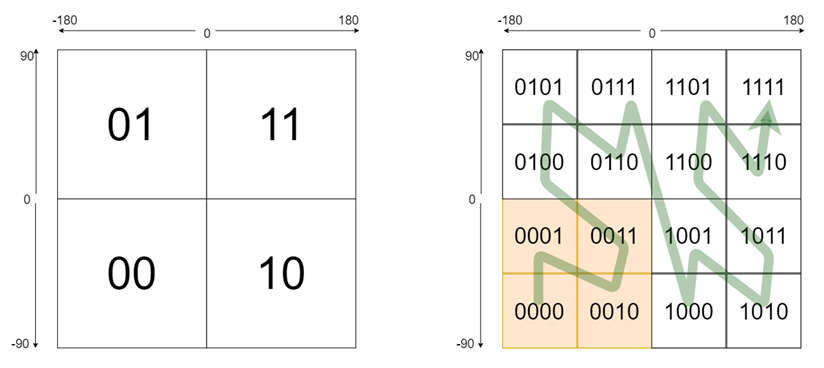
我们先来看经度,[-180,180]可以简单分成两个部分[-180,0]和[0,180],对于给定的一个具体值,我们用一个bit 来标识是在[-180,0]还是[0,180]区间里。然后我们可以对这两个子区间继续细分,用更多的 bit 来标识是这个值是在哪个子区间里。就好比用二分查找,记录下每次查找的路径,往左就是 0 往右是 1,查找完后我们就会得到一个 0101 的串,这个串就可以用来标识这个经度值。
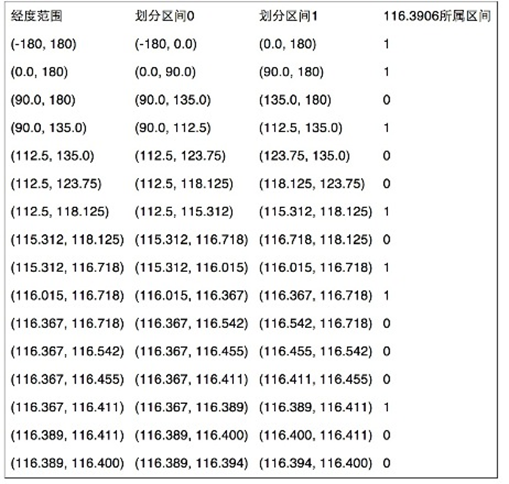
同理纬度也是一样,只不过他的取值返回变成了[-90,90]而已。通过这两种方式编码完成后,任意经纬度我们都可以得到两个由0和1组成的串。
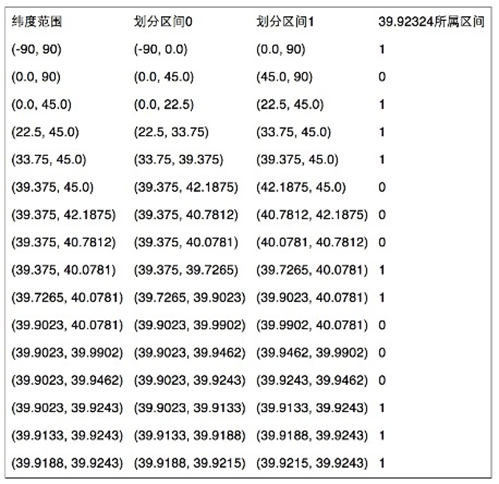
第二步:经纬度二进制合并
接下来我们只需要将上述二进制交错合并成一个即可,这里注意经度占偶数位,纬度占奇数位,得到最终的二进制

1110011101001000111100000010110111100011
第三步:将合并后的二进制做 base32 编码
最后我们将合并后的二进制做 base32 编码,将连续 5 位转化为一个 0-31 的十进制数,然后用对应的字符代替,将所有二进制位处理完后我们就完成了 base32 编码。编码表如下:
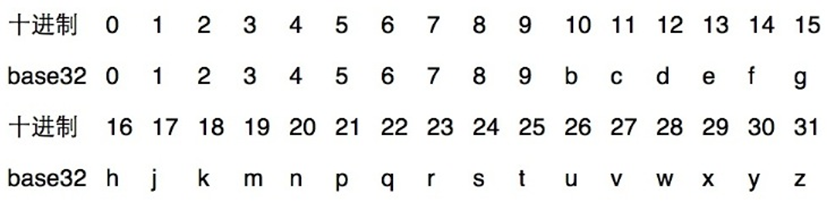
最终得到 geohash 值。
八,HyperLogLog
8.1 简介
在工作当中,我们经常会遇到与统计相关的功能需求,比如统计网站PV(PageView页面访问量),可以使用Redis的incr、incrby轻松实现。但像UV(UniqueVisitor,独立访客)、独立IP数、搜索记录数等需要去重和计数的问题如何解决?这种求集合中不重复元素个数的问题称为基数问题。
解决基数问题有很多种方案:
- 数据存储在MySQL表中,使用distinct count计算不重复个数
- 使用Redis提供的hash、set、bitmaps等数据结构来处理
以上的方案结果精确,但随着数据不断增加,导致占用空间越来越大,对于非常大的数据集是不切实际的。
能否能够降低一定的精度来平衡存储空间?Redis推出了HyperLogLog
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
什么是基数?
比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
8.2 常用命令
# 添加指定元素到 HyperLogLog中,将所有元素添加到指定HyperLogLog数据结构中。如果执行命令后HLL估计的近似基数发生变化,则返回1,否则返回0。
pfadd <key>< element> [element ...]
# 计算HLL的近似基数,可以计算多个HLL,比如用HLL存储每天的UV,计算一周的UV可以使用7天的UV合并计算即可
pfcount <key> [key ...]
# 将一个或多个HLL合并后的结果存储在另一个HLL中,比如每月活跃用户可以使用每天的活跃用户来合并计算可得
pfmerge<destkey><sourcekey> [sourcekey ...]